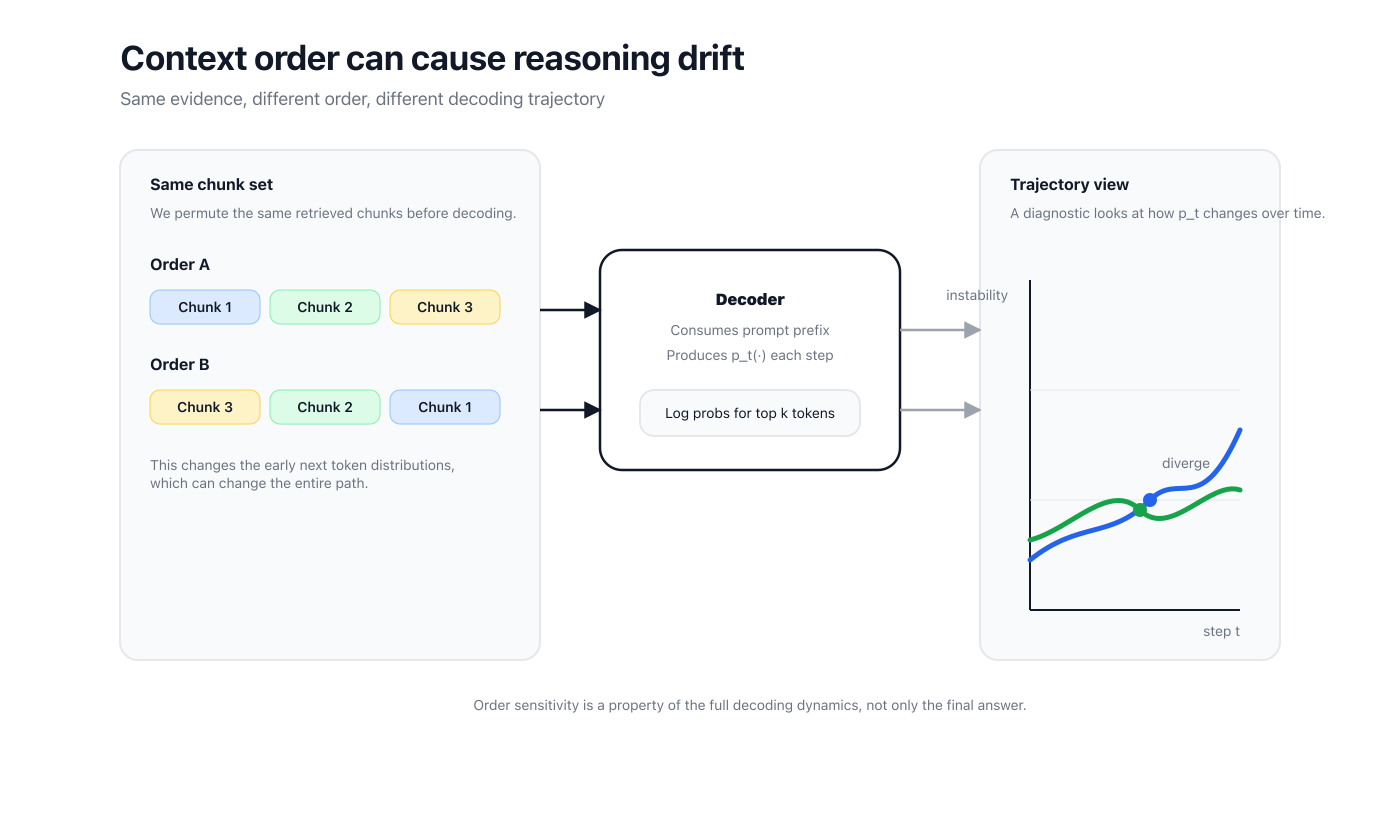
How the same evidence can yield different answers when you only change the order.
People often treat retrieval order as a formatting detail.
In practice, context order can change the early next token distributions, and that can push decoding into a different trajectory.
This post is about how to measure that sensitivity using only token probabilities.
In many retrieval augmented setups, the model receives a question and a set of retrieved chunks.
If you permute those chunks but keep everything else fixed, you often get different answers.
There are two important points.
First, order effects are not rare edge cases.
They show up even with greedy decoding because the model still makes a sequence of locally optimal choices.
Second, the effect is process level.
You can observe drift before the final answer diverges.
At each decoding step , an autoregressive model produces a next token distribution .
Many APIs expose only top candidates with log probabilities.
That is enough.
We can renormalize the logged support and compute lightweight signals from the resulting distribution.
The key idea is to measure two things.
- Uncertainty at a step.
- Distributional change from one step to the next.
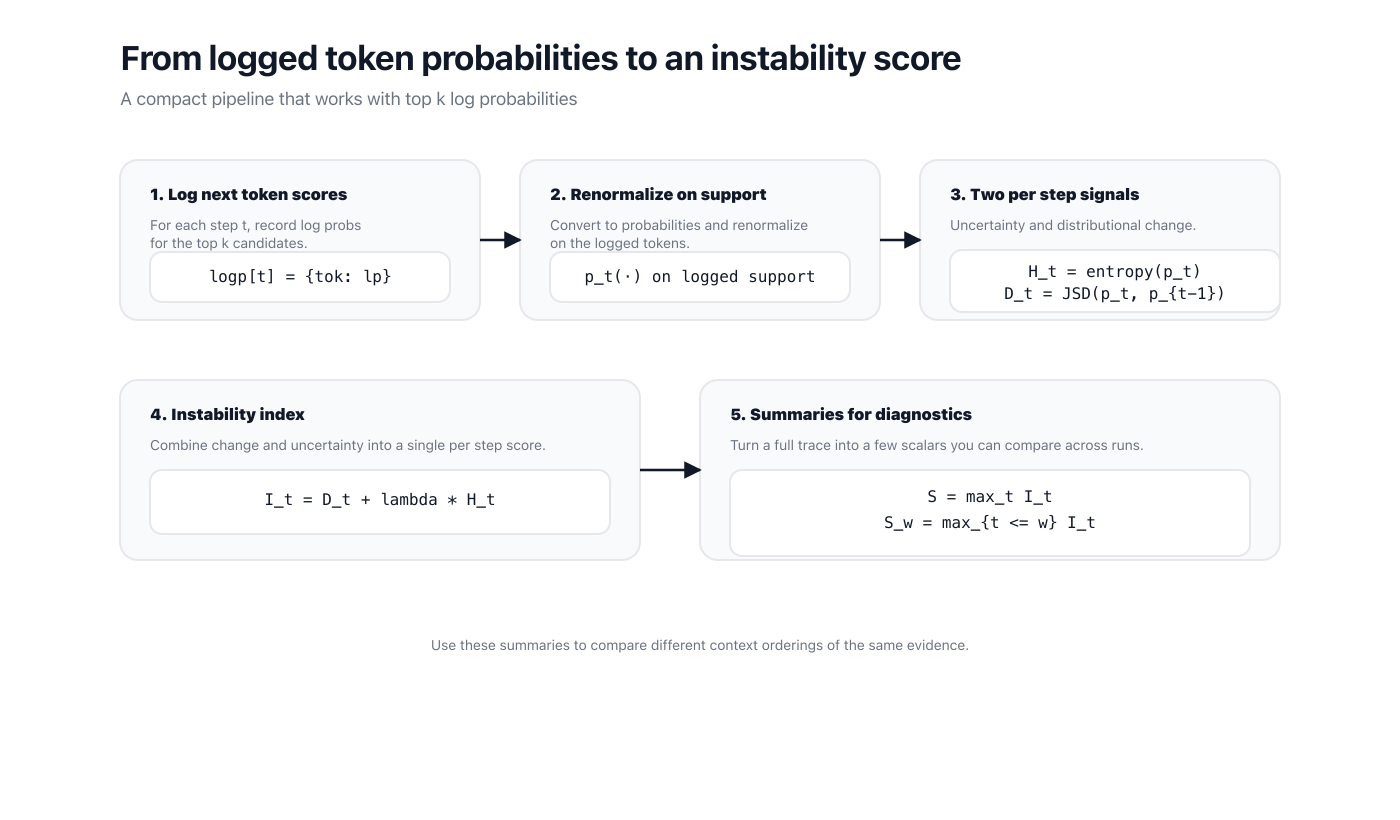
Define an entropy term from and a Jensen Shannon divergence term between and .
Then define an instability index
where is a mixing weight.
I use as a default.
To summarize a trace, use a peak statistic.
For early diagnostics, use prefix windows.
This is simple on purpose.
The goal is not a perfect theory of decoding.
The goal is a consistent metric you can compute across many runs.
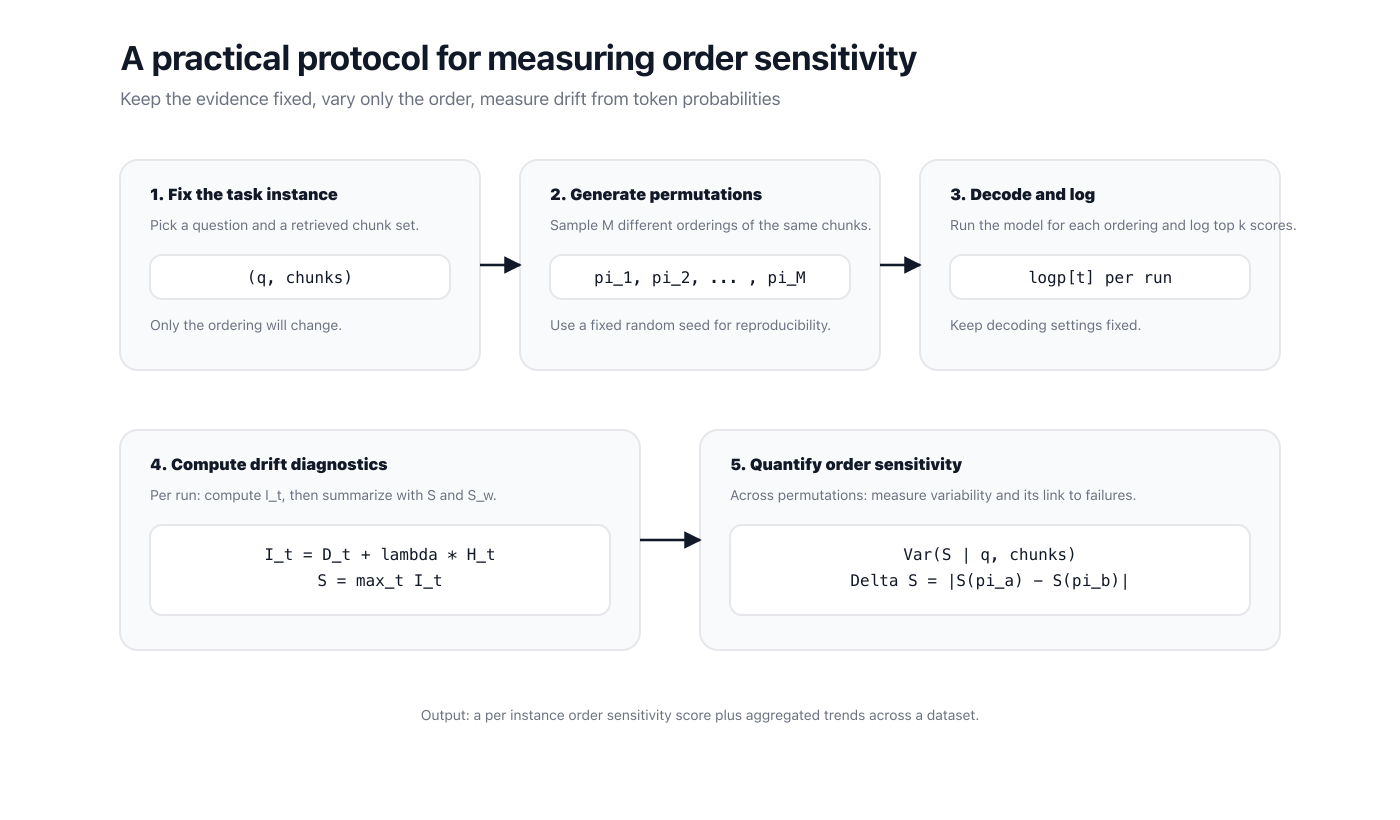
Now we can define a clean protocol.
- Fix a question and its retrieved chunk set.
- Generate multiple permutations of the chunk order.
- Decode with the same settings for each permutation and log top token probabilities.
- Compute , then summarize each run by or .
- Quantify sensitivity from variability across permutations.
You can report sensitivity in several equivalent ways.
- The fraction of permutations that cross a chosen risk threshold.
If you also label runs as correct or wrong, you can test whether higher sensitivity correlates with a higher chance of failure.
What it is.
- A way to measure how much the decoding path changes under context permutations.
- A method that works with logged token probabilities.
- A tool to compare retrieval and prompting strategies by process dynamics.
What it is not.
- Not an intervention.
- Not a claim that you can eliminate order effects with a single heuristic.
A few details matter in practice.
- Keep decoding settings fixed.
- Keep the chunk set fixed.
- Use a fixed random seed for permutation sampling.
- Use the same stopping rules across runs.
If you have access to full vocabulary logits, compute entropy and divergence on the full distribution.
If you only have top logging, renormalize on the logged support and treat the metric as a consistent approximation.