How to detect process-level breakdowns from token probabilities before the final answer fails.
People often describe LLM mistakes as sudden failures: one moment the answer looks coherent, and the next it collapses.
But in many reasoning tasks, a model is not jumping straight from question to conclusion. It is stepping through a sequence of decisions. Small deviations early can quietly reshape everything downstream.
The natural question is:
Not by reading chain-of-thought (which can be incomplete or unfaithful), but by looking at what every decoder produces anyway: a probability distribution over the next token.
In this post I’ll walk through a simple inference-time diagnostic for reasoning drift:
- Training-free (no fine-tuning).
- Black-box (works with logged token probabilities / log-probabilities).
- Process-level (measures how the trajectory evolves, not just the final answer).
At each decoding step , an autoregressive model induces a next-token distribution .
In many APIs, we can only log the top candidates (top- tokens) with their log-probabilities. So we work with a truncated, renormalized distribution over the logged support.
From , we compute two lightweight signals:
- Uncertainty (entropy): when the model is “near a tie” among multiple plausible next tokens.
- Distributional change (Jensen-Shannon divergence, JSD): when the model’s next-token distribution shifts abruptly from one step to the next.
Intuition:
- High entropy = the model is unsure right now.
- High JSD = the model’s “belief over next moves” just changed sharply.
We combine the two into a per-step instability index:
where is entropy, is JSD between consecutive steps, and is a fixed mixing weight (I use as a simple reference).
To summarize an entire reasoning trace, we use the peak instability strength:
And to check “early warning” behavior (to control for length), we also use prefix windows:
- for windows like .
A useful mental model is that decoding is a closed-loop system: each chosen token becomes part of the next input. If the trajectory enters a “fragile” region, a small step-to-step deviation can amplify.
Empirically, instability spikes often coincide with:
- Support turnover: the set of highly probable next tokens changes sharply.
- Near-ties: the top candidates are close, so small shifts can flip the preferred continuation.
These show up directly in , so we do not need hidden states.
As a diagnostic, it’s often predictive.
For example, in one representative GSM8K run (first 300 test problems; greedy decoding), peak instability strength predicts wrong answers with ROC-AUC ≈ 0.66.
The most interpretable view is bucket trends:
- Sort examples by .
- Split into 5 equal-sized buckets.
- Accuracy is much higher in the lowest-instability bucket, and remains low in the higher-instability buckets.
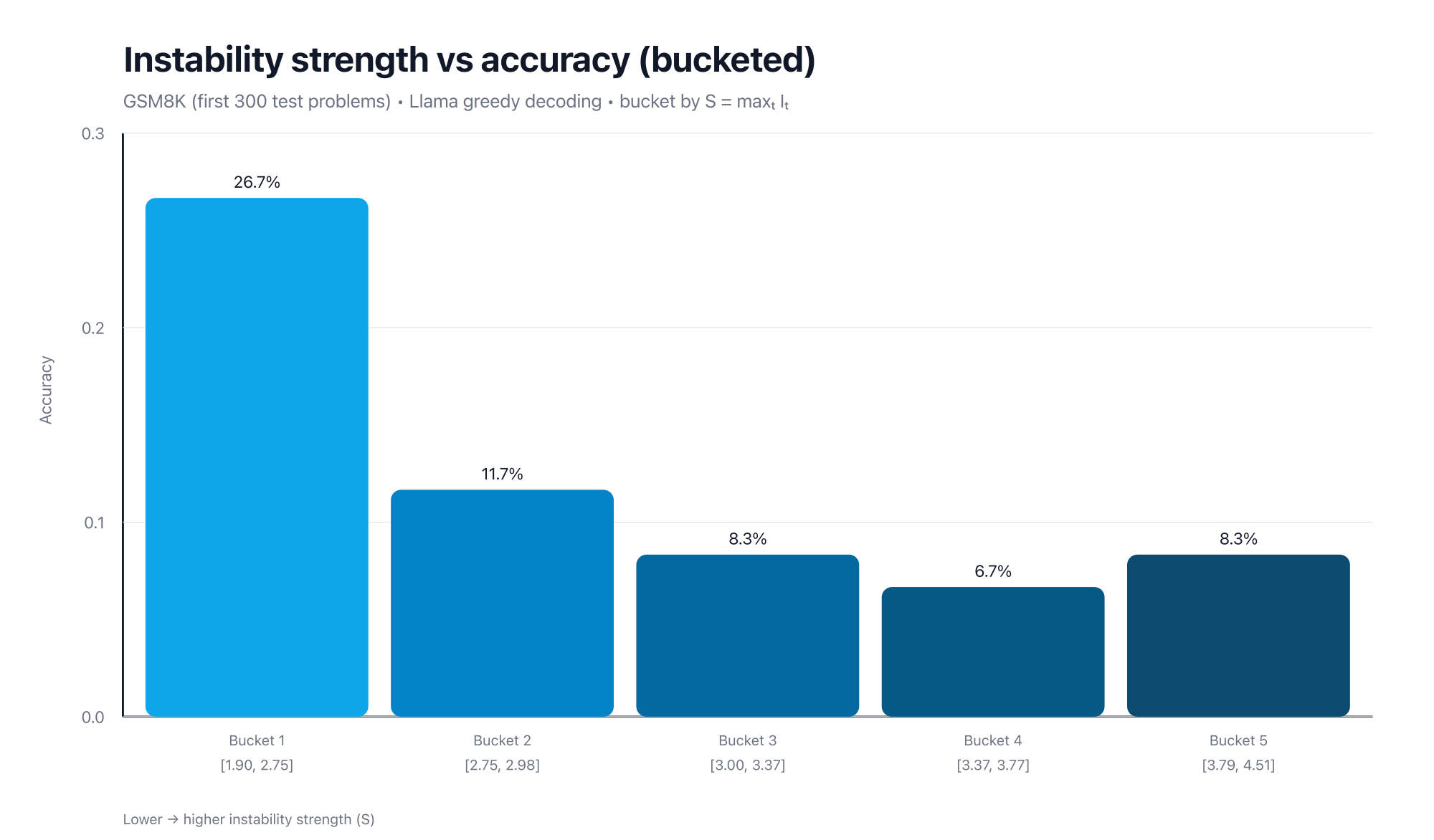
Takeaway:
Higher instability strength corresponds to a higher risk of reasoning failure.
A practical question is whether the signal only appears after the model has already failed.
In the same GSM8K run above, separability is already above chance using short prefixes (e.g., AUC ≈ 0.67 by ) and stays roughly stable as we extend the window.
If the curve looks “flat”, that’s the point: most of the separability is already present very early, so additional steps don’t add much extra predictive power (at least under this summary statistic).
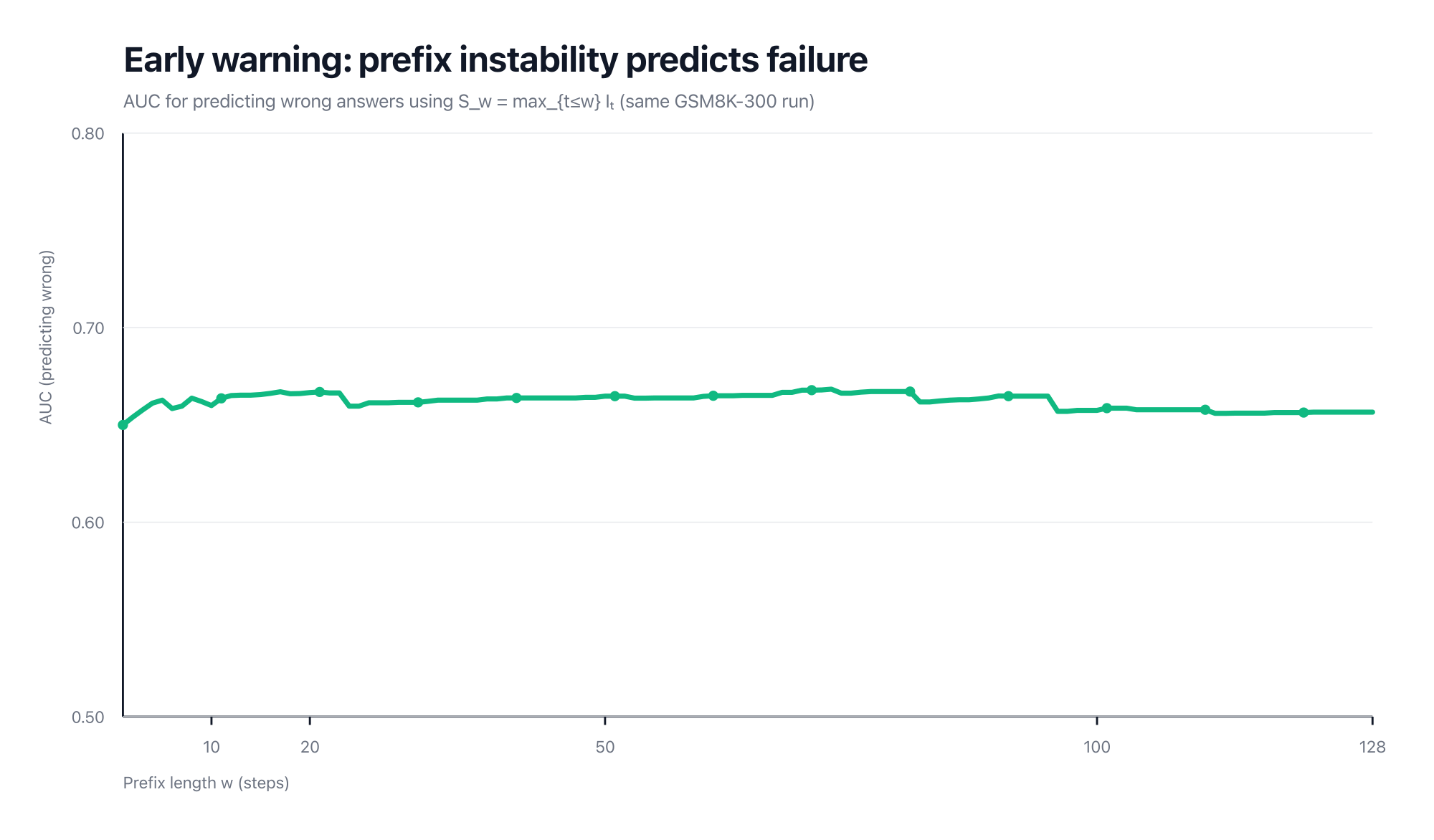
Here’s the most important nuance:
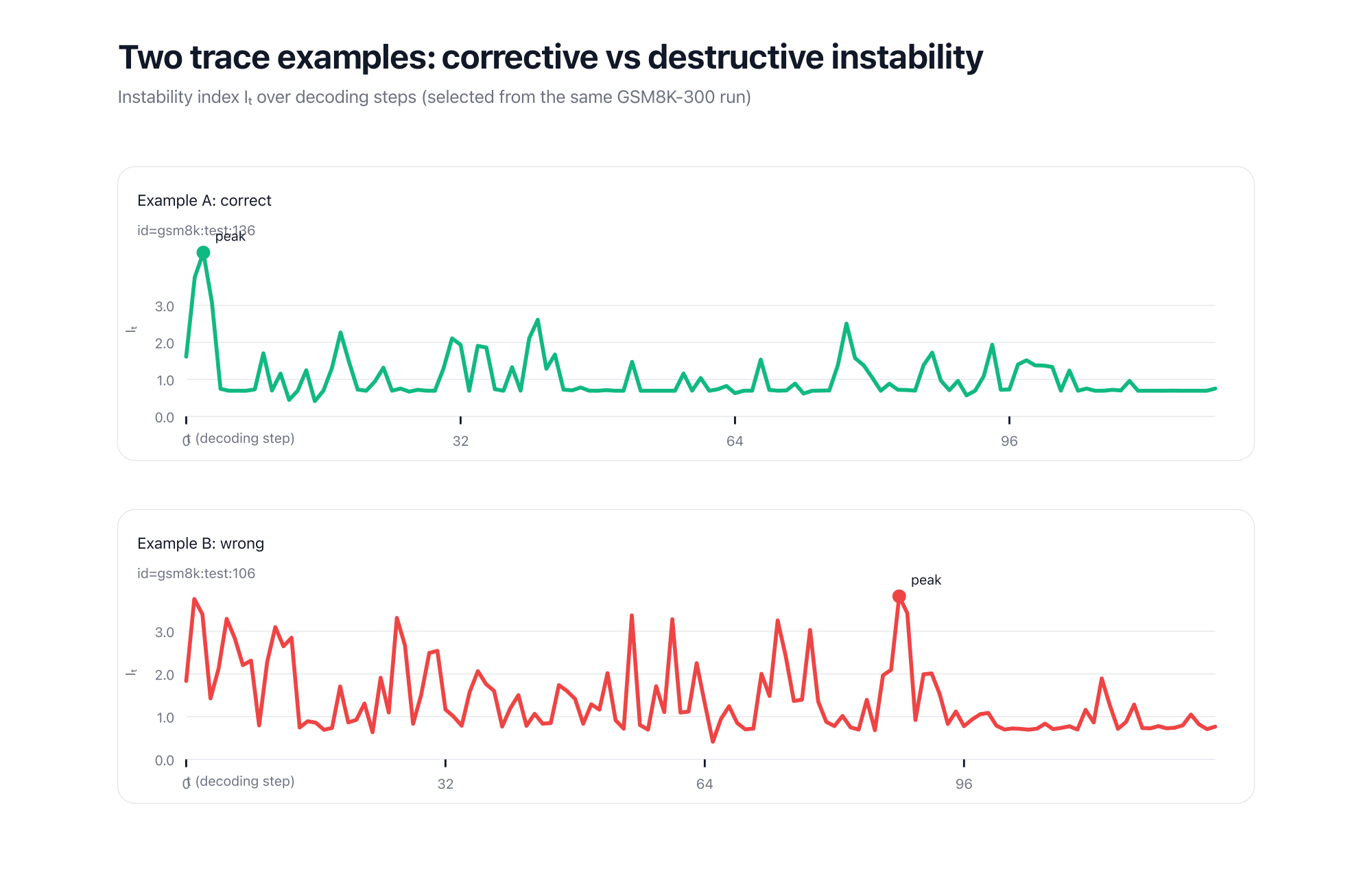
A high instability spike does not automatically mean “the model is failing.”
Sometimes, a model becomes briefly unstable because it is self-correcting (switching from a wrong intermediate route to a better one). Other times, instability happens too late, and the model cannot recover.
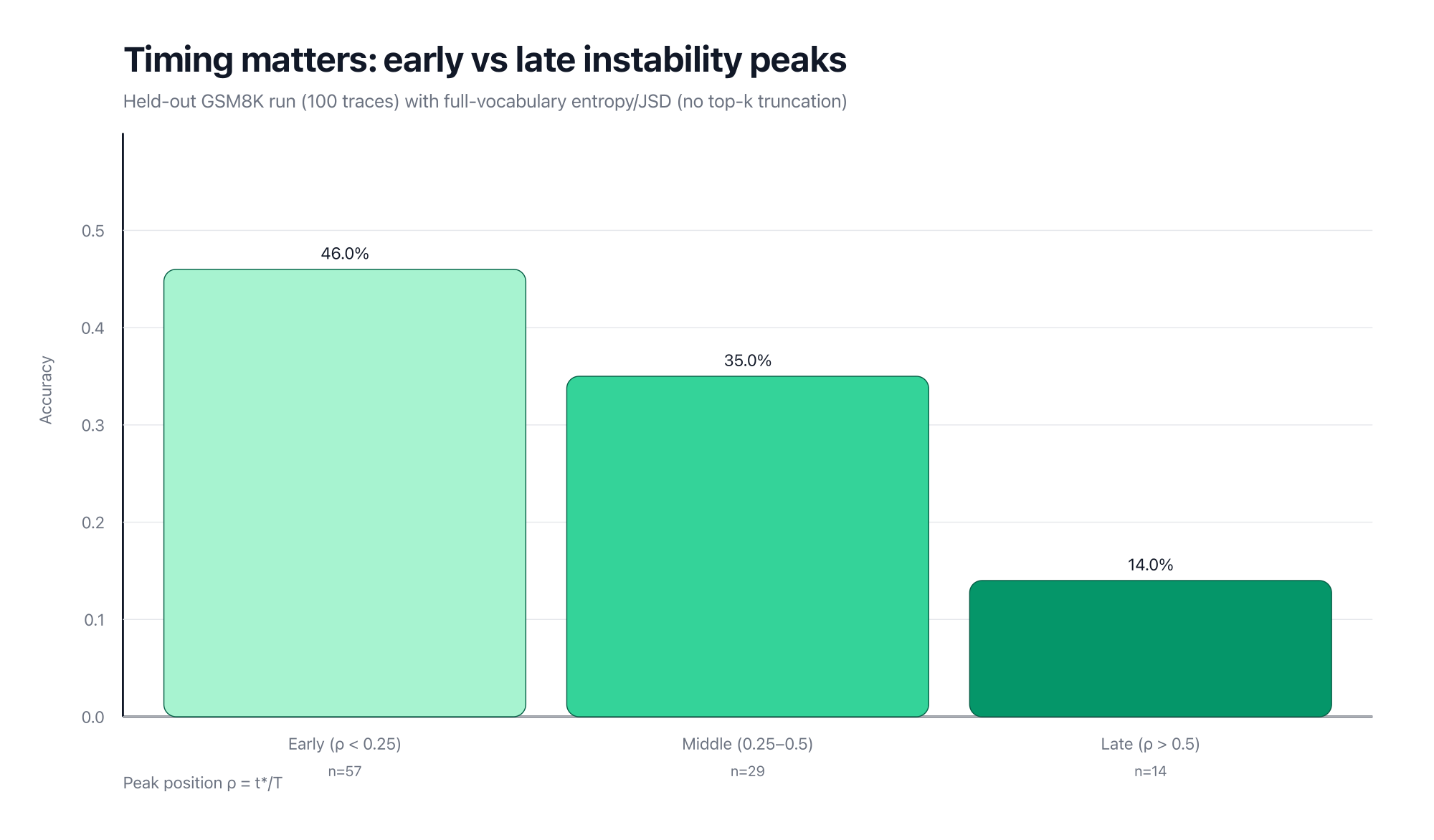
A simple operational proxy is when peak instability occurs.
Let be the peak step, be trace length, and define the relative peak position .
- Early peak (small ): the model has remaining budget to recover.
- Late peak (large ): there may be no time left to stabilize.
As a sanity check beyond top- logging, I also ran a small held-out GSM8K set where entropy/JSD are computed from full-vocabulary logits (no truncation). In that run, early-peak traces are much more accurate than late-peak traces (about 46% vs 14%).
To make this concrete, here are two example traces: one correct with an early peak, and one wrong with a late peak.
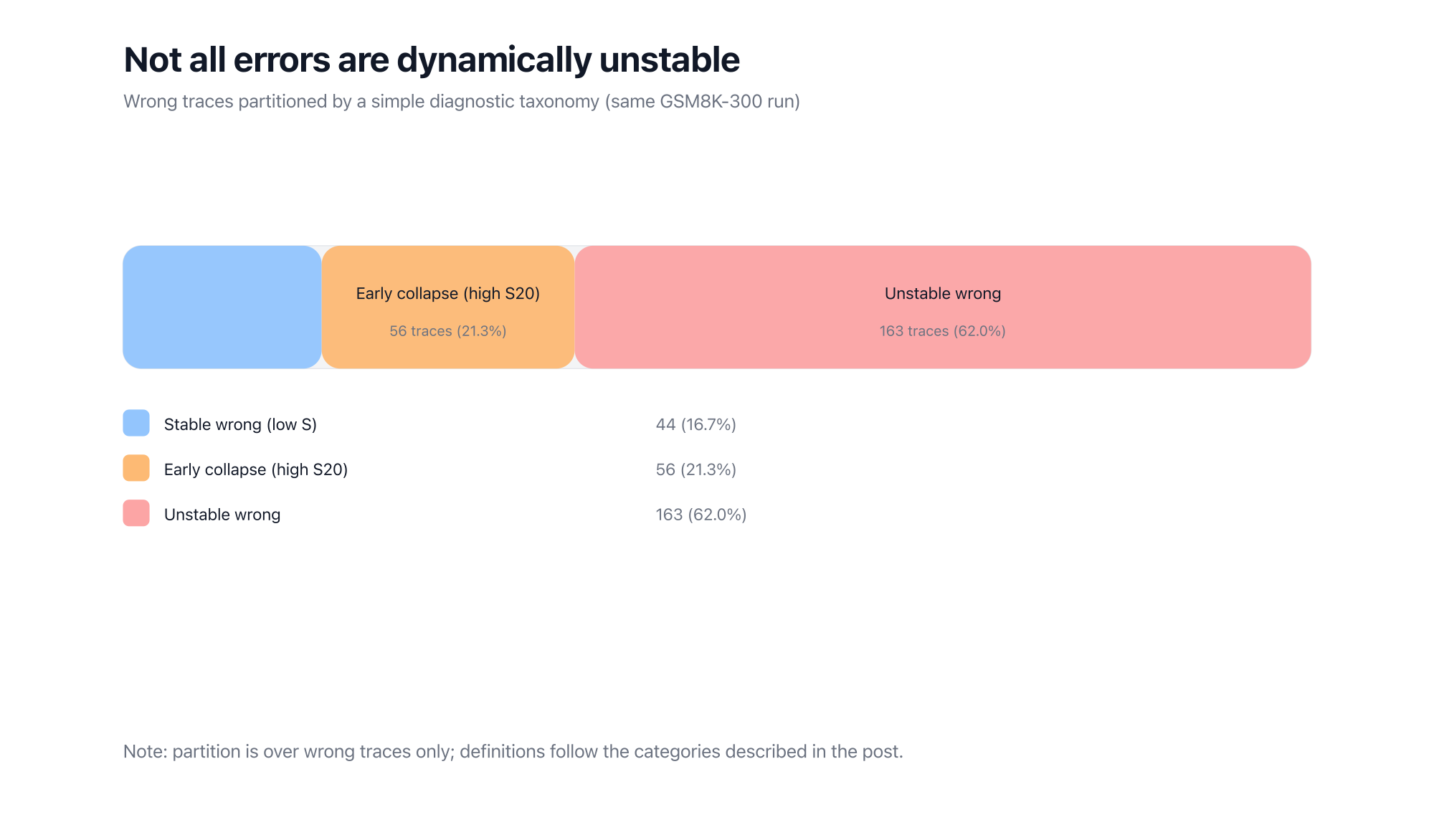
Instability is not a universal explanation of all errors.
Some failures are stable-but-wrong: the model stays confident and consistent, but commits to the wrong solution anyway (knowledge gaps, spurious heuristics, etc.).
This is why I treat instability as a diagnostic dimension, not a catch-all label.
What it is:
- A lightweight, inference-time “health monitor” for reasoning trajectories.
- A way to compare models, datasets, and decoding settings by process dynamics, not just accuracy.
- A tool for studying when and how reasoning collapses.
What it is not:
- Not a stabilization method.
- Not an intervention that claims to improve accuracy.